情報ソースを一元化し確信のある研究戦略を実現
研究支援・推進のためのAIリサーチ・インテリジェンス
研究支援・推進を支える、戦略的リサーチ・インテリジェンス
助成金、研究成果、社会インパクトに関するインサイトを一つのリサーチ・インテリジェンス・プラットフォームで活用、競争力強化や投資判断を支援します。また責任あるAI支援型アナリティクスによって、研究支援・推進部門の意思決定に沿ったレポートを提供します。

データを統合し価値を引き出す
責任あるAIで意思決定を加速する
社会インパクトを示す
リサーチ・インテリジェンスは研究推進、支援のためのプラットフォームです

研究エコシステムを一元的に把握
研究助成金、研究成果、評価、インパクトを、AIネイティブの単一プラットフォームで統合的に把握し、可視性を高めます。

研究資金獲得を加速する
研究の強みや競争力を見極め、助成金獲得の機会拡大を支援します。

研究のインパクトと評価を高める
信頼性と透明性の高いレポート機能により、自機関の社会インパクトを効果的に示します。

レポートを具体的な提案につなげる
AI支援による分析で、トレンドやリスク、次に取るべき対応を明らかにし、データに基づく経営層の迅速な意思決定を支援します。

グローバルな視点で競争力を把握
国内外の他機関とパフォーマンスを比較し、成長の機会を見極めるとともに、戦略立案を強化します。

研究支援・推進部門の業務効率を向上
助成金の特定、報告、研究管理にかかる手作業を削減し、スタッフがより重要な業務に注力できる環境を整えます。
研究戦略・助成金獲得・研究インパクトの意思決定に活かせる洞察
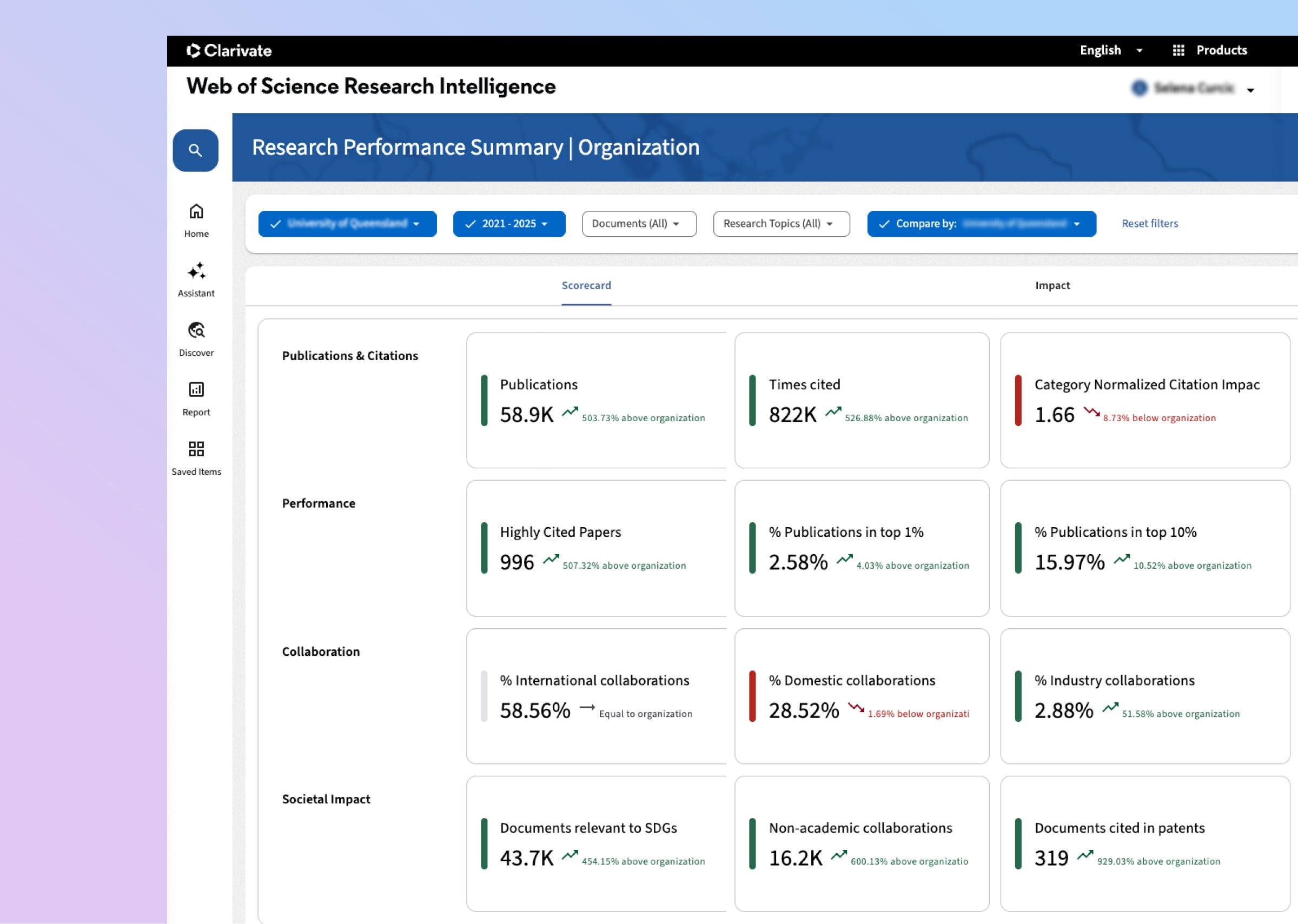
ベンチマークとレポート
他機関と研究実績を比較し、戦略的な計画策定や提案、また経営層への報告を支援します。
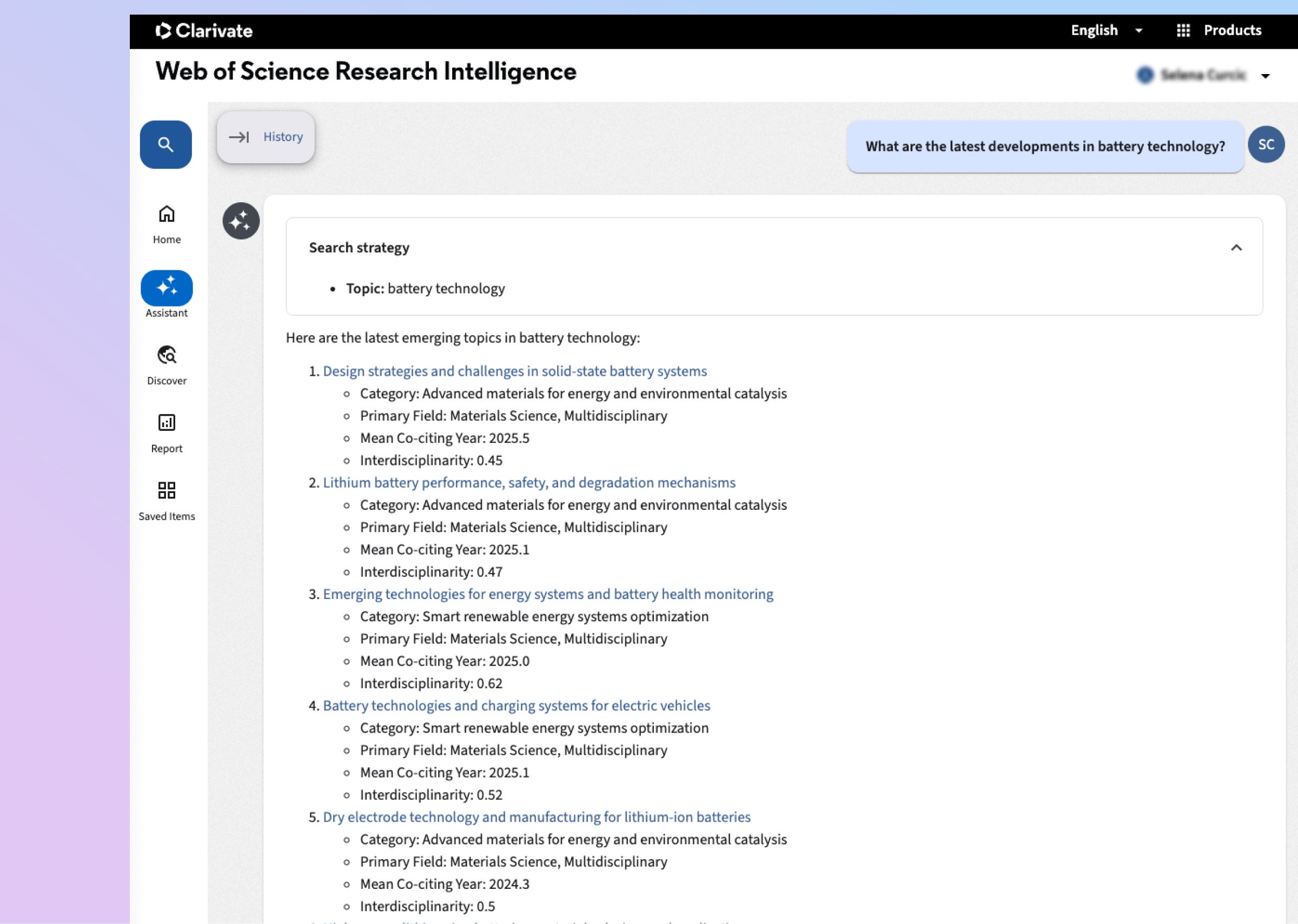
AIによる洞察
AIの活用によりトレンドや機会を特定し、より迅速かつ確信の持てる戦略的意思決定を支援します。
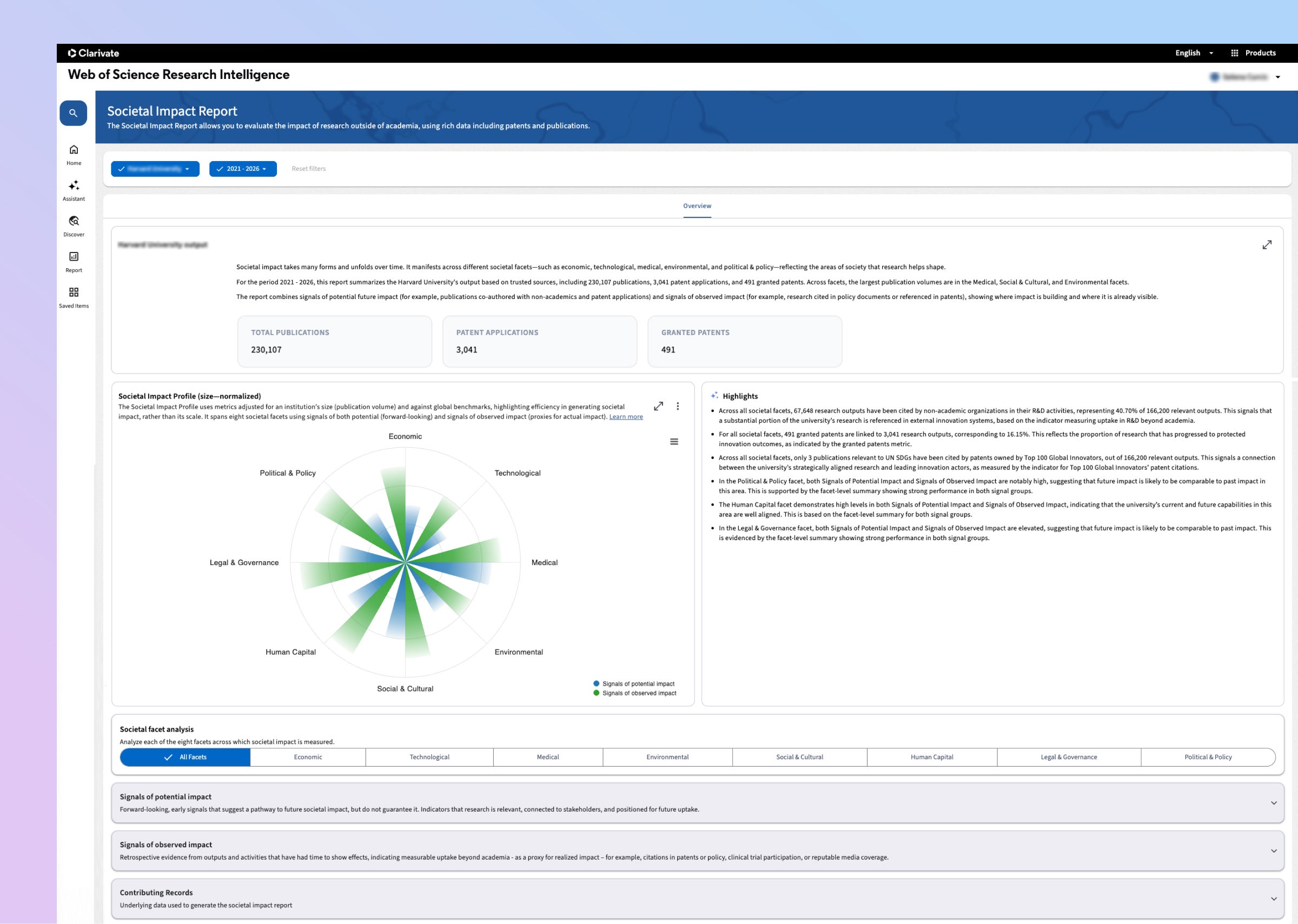
包括的なインパクト
理事会や助成金提供機関、また外部の関係者に向けて、分かりやすく透明性の高い形で、研究がもたらす学術的・社会的な成果を示します。
FAQs
Web of Science Research Intelligence は、以下のような研究戦略立案、研究助成金調達、研究パフォーマンスの評価、また研究成果の報告を担う研究支援・推進部門や学術チームのために設計されています。主な対象者として、以下のような部門にご所属の方や役職の方向けに設計されています。
- 研究推進担当の執行部
- 研究支援・推進部門
- 研究開発部門および外部資金(助成金)担当部門
- 研究マネジメント担当者および研究戦略を担うチーム
- 全学的な戦略立案・評価・分析を担う部門
Web of Science Research Intelligence は、研究助成金の機会の特定、研究パフォーマンスのベンチマーク、成果の報告、そして根拠に基づいた組織戦略の策定を支えるための統合基盤を提供します。
研究支援・推進部門には、研究助成金の獲得率を高め、機関全体の競争力を強化するとともに、研究成果やその価値を明確に示すことがこれまで以上に求められています。一方で、多くの場合、複数の分断されたシステムを使い分け、手作業中心の報告業務が課題となっています。 Web of Science Research Intelligence は、研究活動、助成金、研究成果、社会インパクトに関するインサイトを一つのプラットフォームに統合することで、こうした課題に対応し、より迅速でエビデンスに基づいた意思決定を支援します。
Web of Science Research Intelligence では、論文、特許、研究助成金、政策文書、臨床試験、プレプリントなどを含む研究活動と研究成果を包括的に把握できます。 これらのデータは、Web of Science Core Collection、Derwent Innovations Index patents、Cortellis Clinical Trials Intelligence data、ならびに世界各国の助成金情報データセットなど、クラリベイトの信頼性の高い情報源に基づいており、信頼できるベンチマークやレポーティングを支援します。
AIを搭載した Web of Science Research Intelligence は、研究支援・推進部門のレポーティングを支援するだけでなく、先を見据えた判断に役立つインサイトを提供します。 Research Intelligence Assistant では、対話形式で分析を進めながら、複雑な分析結果を要約し、重要なポイントや新たな機会・リスクをわかりやすく示します。
AIは、次のような業務フローを支援します:
- 戦略的な成長分野や重点分野、機関の強みの特定
- 研究トピックと専門性を助成金の機会につなげる
- 意思決定層向けの報告とインパクトの説明の効率化
- 拡張性の高い、データに基づいた戦略立案
はい。Web of Science Research Intelligence が搭載する Research Intelligence Assistant は、責任あるエビデンスに基づく研究分析を目的として設計されており、一般的なオープンウェブ型の生成AIとは異なります。AIによる回答はすべて、クラリベイトが厳選・整備した信頼性の高いデータセットのみに基づき、それ以外の管理されていない外部情報源を利用することはありません。大規模言語モデルは、自然言語による質問を構造化された分析クエリに変換する役割を担っており、結果は常に取得されたデータに基づいています。また、利用者の入力内容がモデルの学習に使われることはありません。透明性を確保し、誤った回答(ハルシネーション)を最小限に抑えるための仕組みも整えられています。