Research fronts
This essay was originally published in the Current Contents print editions October 10, 1994, when Clarivate was known as the Institute for Scientific Information.
Each year, Clarivate sorts its massive file of bibliographic records created for the Science Citation Index (SCI) and the Social Sciences Citation Index (SSCI). Over 1,000,000 source papers are indexed each year, and the average paper cites approximately 15 references. Two of the search strategies for accessing those indexes in print form, on CD-ROM, or on-line are the Source Index, which is the alphabetic all-author index to what has been published that year, and the Citation Index, which is compiled from the 15,000,000 cited references of which approximately 7,000,000 will be unique. Each of the uniquely cited papers or books will be cited from 1 to 8,000 times.
The first step in identifying research fronts is to create the alphabetic first-author Citation Index. This is then sorted by citation frequency. The most-cited—or core—100,000 papers and books are selected and used as the input for the dictionary of research fronts. These connote areas of significant activity for the year. The next step in the procedure will, in turn, identify several million pairs of co-cited papers. This dictionary of co-cited core papers constitutes the main working file for research front identification. The clustering system developed by Henry Small is used.1 Pairs of documents that have been cited by the same source paper (co-cited) are extracted and then aggregated into clusters that have at least one document in common. We identify approximately 10,000 clusters or research fronts each year. Each cluster is randomly assigned a unique serial number.
All of these procedures have been described in Current Contents many times before.2 A detailed understanding of clustering, however, is not necessary for the practical use of research fronts in SciSearch—Clarivate on-line system available on Dialog, DataStar, DIMDI, and STN. In the following pages, we describe ways to make use of the research fronts searching capability—whether for science policy or information retrieval.
Research fronts are subspecialties—complex keywords, if you will—that are identified by co-citation clustering. The breadth of the subspecialty can vary widely. Its size depends upon the frequency thresholds used. Research front clustering by co-citation or by co-word is a dynamic, self-generating, objective classification system.
Basis of Research Fronts
As explained above, a research front consists of a cluster of co-cited core papers as well as the group of current source papers that cite one or more of these core papers.
Elements of Clarivate Research Fronts
Each research front is uniquely labeled with a serial number which consists of the year, a four-digit random number, and a name [e.g., 92-3056 (Uptake of surfactant protein-B; casein kinase-II; catalytic subunits)].
Year. The last two numbers of the data year from which the front was generated are the first two digits of the research front serial number. Therefore, all research fronts generated from the combined 1992 SCI / SSCI would be labeled with an initial “92-.”
Serial Number. The second part of the research front number is a randomly assigned four-digit number. Each of the one million papers indexed each year will be assigned to one or more research fronts, provided it has cited one of the core papers mentioned above. The computer checks each reference to determine whether it is one of the 100,000 core papers in the dictionary. It then assigns the research front labels, which are essentially indexing tags, to each. The labels facilitate calculation of the weight.
Weight. For each paper, a weight is calculated that indicates the number of core papers for that research front cited in that paper (e.g., if three of these are core to a particular research front, then the weight is expressed as “003” and is shown in the on-line identifier listing). In the listing in Figure 1, the weight appears in the fourth column, just after the research front number. This list is an excerpt from the list of 8,375 research fronts for 1992.
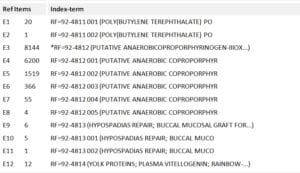
Figure 1. Excerpt from 1994 SciSearch® file.
In case of a small cluster like 92-4811, it is not necessary to use the weighting factor. Instead, one would proceed to look at the 20 retrieved papers on poly(butyl terephthalate). However, to conduct a more focused search for a highly active research front, as in the case of 92-4812, the weight makes it possible to focus the search. Thus, for research front #4812, line E8 indicates that there are only 4 papers that have cited 5 of the core papers for that research front, 55 papers have cited 4, 366 have cited 3 core papers, and 1,519 have cited 2 core papers. The 6,200 other papers are “relevant” to the search, but normally such a large set would be combined with other search parameters to reduce retrieval to manageable proportions. Those parameters could include another research front tag, a keyword, country, or even a single cited reference.
A low number for weight could indicate the presence of tangential works, while a high number could indicate either highly relevant research or a review article. Knowing the article type allows appropriate interpretation of the weight.
Name. The research front’s name is shown in the last column in Figure 1. It is derived from the most frequently occurring words and phrases used in titles of the citing (source) papers. This naming procedure is similar in concept to the process of creating KeyWords Plus for Current Contents on Diskette 3 , SciSearch, Social SciSearch, Current Contents Search, and Arts & Humanities Search.
Co-Citation Clustering
Bibliographic coupling occurs when two publications cite one or several other publications in common 4. In contrast, co-citation occurs when two publications are cited by a third, later publication 1. The greater the frequency of co-citation of a given pair, the greater the likelihood that it defines an established or emerging topic or subspecialty. The citation pair can be used in a citation index search to retrieve related publications. One pair can usually identify a small research front, but active research fronts generally involve several interrelated co-citation pairs 5. The larger the number of pairs included in a cluster, the broader the scope.
Single-link clustering, for which the computer selects a single document and searches for all the other items that are linked to it, is used to form clusters of co-cited papers. With the papers that cite them, research fronts are identified 6. Frequency thresholds are used to modulate clustering by controlling the relative number of pairs selected. With either co-citation or co-word analysis, the scope can be adjusted by increasing or decreasing the threshold. In other words, the larger the number of pairs included in the cluster, the broader the scope. This concept is important when trying to create maps of the literature at different levels of detail. Threshold strength refers to the degree of association between co-cited pairs in terms of the proportion of their total citations that are co-citations 2.
Co-Word Clustering
An alternative to co-citation clustering is co-word clustering, which focuses on analysis of the title or keywords used by authors 7. Clarivate uses co-word clustering in its Permuterm Subject Index section of the SCI or SSCI 8. Co-citation and co-word methods can be combined in an analysis. This helps to overcome the limitations of co-citation clustering in certain forms of literature, especially where referencing is limited 9. Tony van Raan and his colleagues have used a combination of these techniques in many of their scientometric studies, such as their study of literature on atomic and molecular biology, and have found that the combination of methods allowed them to gain a clearer picture of the cognitive content of publications 10.
In a review of Callon’s work on co-word analysis, Small points out that “if co-word links are viewed as translations between problems, co-citation links have been viewed as statements relating concepts. 11” Each offers an interesting perspective on analysis of literature and helps in the identification of research fronts. Combining the aspect of cognitive content with the broader view of co-cited publications affords this enhanced insight.
The “Invisible College” Connection
While research fronts are essentially a posteriori constructs that provide both highly specific and broad access to subject matter, they can be combined with a priori classification systems if desired. However, the term “invisible college” is generally used to characterize dynamic research areas involving groups of researchers as, for example, the invisible college on “chaos in life sciences. 12” The authors are its faculty, and both core and citing authors may or may not be members of these research communities 13.
Rankings
Using Clarivate on-line SCISEARCHsystem, data can be ranked to reveal interesting facts about performance and trends. Among the fields available on-line for ranking analysis are:
- most cited author
- most prolific author
- most active institution or lab
- most active research front.
Journalists, among others, often want to know the key people or labs working in a given area. For large institutions or regions, one may want to learn the types of research emphasized there. In many of my lectures, I have presented a list of the most active research fronts for that country. These insights can be of value for planning purposes.
Conclusions
From a scientific management perspective, it is interesting to observe changes in research front activity over a multiyear period. A new field could be associated with a small group of key papers. As that literature grows and the field grows, new branches are created. Using the Clarivate research fronts files, one can then trace the evolution of the field through its many stages of growth and decline. It is interesting to see what has happened in the past (which strong research fronts have persevered), what is happening now, and what might happen in the future. The relationship to research evaluation should be apparent. Kostoff, for example, predicts that federal use of co-occurrence techniques (research front analyses) will increase in the near future as these systems become better understood and easier to use 14.
Graphic presentation of research front information in the form of co-citation maps is an important by-product of the system involved here. That topic will be the subject of the next essay 15.
Dr. Eugene Garfield
Founder and Chairman Emeritus, ISI
References
- Small H S.Co-citation in the scientific literature: a new measure of the relationship between two documents. J. Amer. Soc. Inform. Sci. 24:265-9, 1973.
- ——————.The ABCs of cluster mapping. Part 1. Most active fields in the life sciences in 1978. Essays of an Information Scientist. Philadelphia: ISI Press®, 1980, Vol. 4. p. 634-41.
- Garfield E G.KeyWords Plus®: ISI®’s breakthrough retrieval method. Part 1. Expanding your searching power on Current Contents on Diskette®. Essays of an Information Scientist. Philadelphia: ISI Press, 1990, Vol. 13. p. 295-9.
- Kessler M M.Bibliographic coupling between scientific papers. Amer. Doc. 1410-25, 1963.
- Garfield E G.New tools for studying the history of science. Essays of an Information Scientist. Philadelphia: ISI Press, 1988, Vol. 11. p. 20-1.
- ——————.History of citation indexes for chemistry: a brief review. Essays of an Information Scientist. Philadelphia: ISI Press, 1985, Vol. 9. p. 42-7.
- Zitt M, Bassecoulard E.Development of a method for detection and trend analysis of research fronts built by lexical or co-citation analysis. Scientometrics 30(1):333-51, 1994.
- Garfield E G.How to use Science Citation Index® (SCI®). Essays of an Information Scientist. Philadelphia: ISI Press, 1983, Vol. 6. p. 53-60.
- Callon M, Law J, Rip A (eds). Mapping the Dynamics of Science and Technology. London: MacMillan. 1986.
- Braam R R, Moed A F, Van Raan A F J.Mapping of science by combined co-citation and word analysis, part II: Structural aspects. J. Amer. Soc. Inform. Sci. 42:233-51, 1991.
- Small H S.Book review of Callon et al. Scientometrics 14(1-2):165-8, 1988.
- Sankaran N.Chaos theory finding new applications in life sciences. The Scientist 8(16):3,9, 1994.
- Crane D.Invisible Colleges: Diffusion of Knowledge in Scientific Communities. Chicago: University of Chicago Press, 1972.
- Kostoff R N.Federal research impact assessment: State-of-the-art. J. Amer. Soc. Inform. Sci. 45(6):428-40, 1994.
- Small H, Garfield E.The geography of science: Disciplinary and national mappings. J. Inform. Sci. 11:147-59, 1985.