Why structured and categorized research data are essential for search, discovery and analytics

The Institute for Scientific Information (ISI) report, Research categorization and the value of structured data, explains how rigorous data curation, taxonomy and metadata standards at Clarivate enhance search, discovery and analytics, and highlights what can go wrong if good data structure and categorization are ignored.
In an era defined by research acceleration, global collaboration and unprecedented data volumes, the ability to structure and categorize research information is no longer a technical preference — it’s a strategic necessity.
Every year, millions of articles, datasets, patents, preprints, conference proceedings and policy documents enter the research ecosystem. Without consistent metadata and robust classification systems, this vast body of work becomes difficult to search and more challenging to analyze effectively.
For research institutions, funders, and policy makers, the consequences are significant: inefficient discovery, incomplete evidence for decision-making and reduced visibility of research strengths — and, ultimately, decisions made on misleading or incomplete data.
The examples below, drawn from our latest ISI report and informed by decades of methodological development and consistent and comprehensive indexing in Web of Science, show what happens when data structure and categorization break down — and why lightly structured or incomplete data can produce confident‑looking but flawed conclusions. This is a risk that increases as datasets prioritize scale or openness without the same level of editorial control and long‑term maintenance. They also highlight why researchers, analysts, and research managers need to understand and mitigate the risks this creates.
Misinterpreting research performance when time metadata are incomplete or inconsistent
One of the most common errors when using citations in search and analysis is comparing raw citation counts across years. The report shows that when plotting a simple average of citations per paper, values always drop toward the present. This has nothing to do with declining quality — newer papers simply haven’t had time to accumulate citations.
In Figure 1, using data from the Web of Science Core Collection, the United Kingdom and Germany appear to decline sharply in research impact when using simple citation averages. But once citations are categorized by year (as well as subject and document type), producing Category Normalized Citation Impact (CNCI), the trend reverses. Both countries/regions show stable or rising impact.
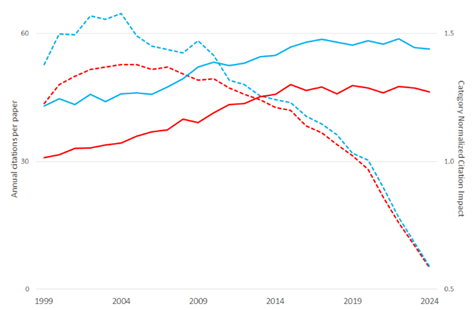
Figure 1. Calculations of annual citation impact for the U.K. (blue) and for Germany (red). The dashed lines show the result using a simple average of citations accumulated to date for the papers published each year. The solid lines show the result when these same citation counts are normalized against the global average for the Web of Science subject category to which the journal is assigned, document type, and the year of publication (CNCI). (Data source: Web of Science Core Collection.)
The example above shows how time information is a critical component of research publication metadata. The completeness and accuracy of these data depend on comprehensive cited references for historical literature and cover-to-cover indexing of journals, which help prevent gaps and risk of misinterpretation.
Moreover, the inability to distinguish between the date of first accessibility online (also known as Early Access date) and the final publication date of a paper, can create “phantom trends” in citation impact that reflect publishing practices, not research impact. Analysis in the absence of structured indexing of both initial online and final publication dates may lead to false conclusions.
Comparisons become misleading without consistent discipline and document-type categorization
Research cultures differ profoundly between fields. Biomedicine publishes short, frequent papers with large citation pools. Engineering publishes more slowly and often in conference proceedings. Humanities rely on monographs that gradually accumulate citations over years.
The report’s analysis shows that:
- biomedical papers plateau at high citation counts
- engineering papers plateau at much lower levels
- humanities monographs may take years to be cited.
If institutions compare “average citations per paper” without adjusting for these discipline differences, engineering or humanities units will always appear weaker — even when producing world leading research.
Example: In Figure 2, a 1999 biochemistry paper gathers around 60 citations after 25 years, while an engineering paper remains in single digits. Without categorization, this looks like “impact disparity,” when in fact it reflects discipline norms.
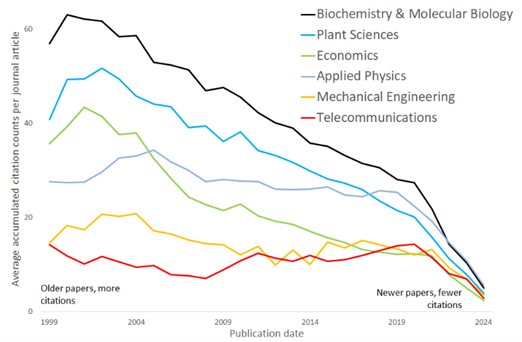
Figure 2. Average accumulated citation count per journal article rises over time and does so at different rates in different subjects; e.g., a biochemistry article is cited 5 times on average in 2024, but the average citation count for 1999 articles has risen over 25 years to 60. This analysis shows five of 254 specific journal-based subject categories in Web of Science. These categories account for detailed cultural differences between subjects and support management information.
This exemplifies the importance of accuracy, breadth and depth of subject categorization of research activity. Editorial curation of Web of Science journal categories ensures their accuracy. The journals indexed in Web of Science Core Collection are assigned to 254 categories, which are mapped to the subjects used in other classification schemas (Essential Science Indicators, Global Institutional Profiles, OECD, U.K. REF, Australia ERA etc.). This is complemented by document-level subject categories: nearly 2,500 Citation Topics at the most granular level, mapped to 17 SDGs, and 10,000 Emerging Topics. Flexibility of selecting appropriate subject categorization becomes essential in normalizing citation impact.
Citation rates vary between document types, with reviews typically cited at higher levels than research articles. Therefore, correct assignment of document type metadata is also critical for both normalization in citation-impact analysis and interpretation of trends. As these metadata come directly from publishers, and lack consistency across sources, there is a need for a standardized definition of each document type (e.g. document types in Web of Science) and curation of the information provided by publishers.
Discovery breaks down when less conventional literature is unstructured
Grey literature (policy reports, technical documents, and government publications) is often rich in insight but poor in metadata. Without document type, subject categorization and structured reference metadata:
- key sources fail to appear in searches
- analysts cannot trace evidence back to its research base
- policy impact is underreported.
A researcher looking for foundational work on a social policy topic may miss the most influential government report if the databases they search lack structured metadata.
The Research Topics classification recently developed by Clarivate, and implemented in Web of Science Research Intelligence, provides a unified, content-driven taxonomy designed to organize diverse research outputs beyond traditional citation-based methods. This approach enables multiple topic assignments and allows consistent classification across publications, patents, grants, and other outputs, supporting cross-platform discovery, interdisciplinary analysis, and evaluation of the societal impact of research.
Collaboration effects distort citation indicators when collaboration mode isn’t categorized
International collaboration systematically boosts citation performance. Figure 3 provides striking evidence using data from Web of Science Core Collection: countries/regions with high collaboration rates (Australia, Germany, the U.K.) show higher CNCI values than when citations are normalized by collaboration type (Collab-CNCI). For Australia, CNCI drops from 1.50 to 1.06 when collaboration is correctly accounted for.
Neglecting collaboration structure leads to flawed benchmarking and misguided policy decisions.
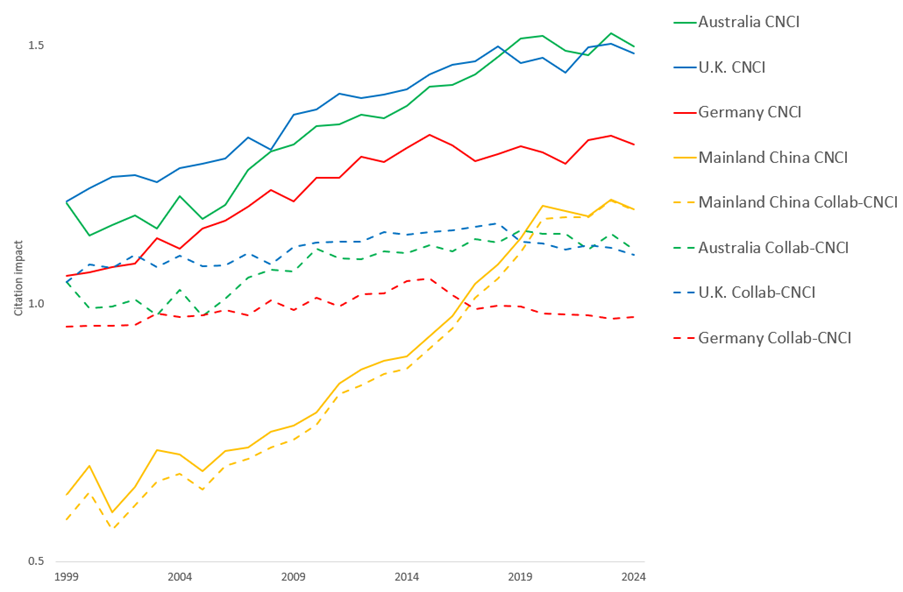
Figure 3. Trends in annual national citation impact illustrating the effect of using Collab-CNCI: categorizing papers by mode of international collaboration prior to normalizing citation counts by year and subject to calculate impact. For Australia, Germany and the U.K., the net standard citation impact (CNCI) is visibly higher than when collaboration mode is taken into account (Collab-CNCI). Mainland China has much less frequent international collaboration and its citation impact is affected very little. (Data source: Web of Science Core Collection)
This example emphasizes not only the importance of collaboration type as an extra category in structuring research activity data, but also a critical need for correct affiliation metadata.
Why structure is essential
Ultimately, structured research data is a form of critical infrastructure — invisible when working well, hazardous if missing or poorly maintained. It is essential for confident decision making, supports transparent evaluation, and gives researchers and research offices the tools they need to navigate an increasingly complex global environment.
Our ongoing commitment to rigorous, reliable categorization ensures that the research community can continue to explore, analyze and act on the world’s knowledge with clarity and confidence.
Download and read the ISI report: Research categorization and the value of structured data
Learn more about the Web of Science Core Collection




Related insights
The latest news, technologies, and resources from our team.





